Intel CLDEMOTE, un cambio en la caché que permitirá un aumento de IPC en procesadores 10nm++

Los procesadores de 10nm de Intel son muy esperados y ya deberían estar en todas las gamas de productos, no solo en portátiles. Según la última filtración, que no viene directamente de Intel, los 10nm podrían llegar el próximo año. Según han descubierto, los 10nm++ para sobremesa llegarán el próximo año con grandes mejoras. La más notable será la mejora de las cachés mediante CLDEMOTE.
Dentro de la documentación oficial de Intel para la 39 edición de las extensiones ISA, el usuario InstLatX64 ha encontrado esta referencia a CLDEMOTE. La documentación cuenta con un apartado para los sets de instrucciones extendidas como característica para los nuevos Intel 64 con IA32. Cada set tiene una asignación de arquitecturas, que da a entender su soporte.
[amazon box=»»]Intel preparada un cambio en la caché mediante CLDEMOTE
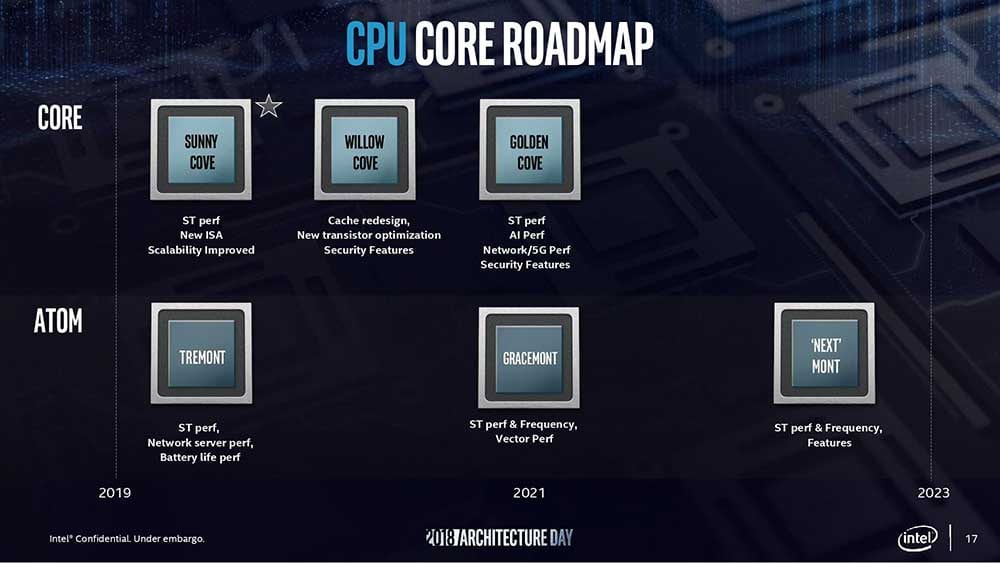
Esta novedad que se ha descubierto afecta a las cachés y a su interacción con la memoria RAM. Básicamente se modifica la caché y los niveles de la misma y se empezará a implementar en Tremont, Alder Lake y Sapphire Rapids. Posiblemente para esto se necesiten velocidades de memoria RAM superiores a las actuales, así que ya hablaríamos de DDR5.
Cabe destacar que estas modificaciones lo que supondrán es un gran aumento del IPC de los procesadores de Intel. CLDEMOTE estaría lista desde hace tiempo, aunque de momento solo ha sido nombrada en documentos oficiales de manera un tanto ambigua. Aunque la primera referencia es de octubre de 2018, parece que nadie se había percatado de ella.

Pese a que aparecía nombrada, no estaba asociada a ninguna arquitectura en concreto. Mediante al último Roadmap de Intel, ahora sabemos cuando llegará esta nueva función. El set de instrucciones CLDEMOTE es una mejora que se denomina “instrucciones de sugerencia de cachés”
Será un gran cambio para el diseño de instrucciones e impactará directamente en el rendimiento. Pese a que su explicación es simple, su implementación es compleja. Básicamente mueve determinadas líneas de caché de datos desde las cachés más próximas al núcleo hacia las más alejadas. Intenta optimizar por tanto el rendimiento de las cachés mediante el movimiento de datos hacia la caché L3 en vez de estar en L2 o L1.
No todo es tan sencillo
Para esto se necesitan una metodología que garantice su buen funcionamiento:
- Necesaria una transacción de caché que garantice su corrección
- Se debe garantizar la escritura de las caches en la memoria volátil
Este sistema parece que supondrá algunas dificultades a la hora de sacar el máximo rendimiento. Además, genera una mayor dependencia del rendimiento de las cachés, al mismo tiempo que se aumenta el IPS. Pero el movimiento de las dos primeras caché a la caché L3 se consigue una mejora de rendimiento.
Desde el punto de vista de las cachés, aumenta la complejidad y también los costes del desarrollo de procesadores. Además, el tiempo de acceso de la RAM y la velocidad de esta pasan a tener una gran importancia, como pasa en AMD.



