
Índice de contenido
AMD con RDNA busca centrarse en los videojuegos, frente a GCN que era un diseño hibrido, reduciendo el consumo para aumentar el rendimiento.
Esta pasada noche/madrugada se han presentado las nuevas AMD RX 5700 XT y RX 5700. Las nuevas tarjetas gráficas de la compañía se basan en la arquitectura Navi. Para el desarrollo de Navi se ha desarrollado RDNA, un nuevo sistema de diseño con nuevas tecnologías para mejorar el rendimiento y la eficiencia. Sobre todo se busca con este nuevo diseño maximizar el rendimiento en juegos para poder competir de manera directa con NVIDIA.
GCN era un diseño hibrido entre el gaming y la computación masiva de datos, pensando en este caso para segmentos profesionales. El problema residía en que las versiones para gaming no estaban a la altura de NVIDIA y tenían un consumo desmedido. Se debe a que estaban pensadas para la fuerza bruta, sin importar la eficiencia energética, de ahí los elevados consumos. Pero con RDNA cambia la cosa, ya que se ha pensado específicamente en el gaming, optimizando para este mercado.
Primera iteración de Navi basada en GCN + RDNA
Saltar de GCN a un diseño RDNA de manera directa no es viable, porque este nuevo proceso añade tecnologías que no existían. No existe optimización para RDNA o es aún muy primaria y por esto se busca una combinación con GCN. La primera iteración de Navi será un hibrido entre los dos sistemas, buscando ofrecer potencia y ajustar el consumo. No será hasta Navi 20 cuando veamos gráficas puramente RDNA y veamos de que es capaz este nuevo proceso de fabricación.
GCN es una gran arquitectura para cálculos matemáticos pesados gracias a su gran rendimiento en TFLOPS y a su paralelización. La Radeon Vega 64, según sus características, debería pulverizar a la GTX 1080, pero no lo consigue. Eso se debe a que en el uso de los núcleos y las caches para juegos no es muy buena.
Navi mejora la eficiencia en estos campos, porque según AMD, tiene una nueva combinación de unidades de computo. Además, dispone de una nueva jerarquía de caché multinivel y un flujo gráfico optimizado.

Así es Navi internamente
La compañía ha presentado dos gráficas basadas en Navi. La primera es una implementación completa de Navi, mientras que la segunda es una versión reducida. Dos versiones que difieren únicamente en la cantidad de Compute Units.
Navi 10 cuenta con 40 Compute Units y cada una de estas Compute Units dispone de 64 Stream Processors. Una sencilla multiplicación nos certifica los 2 560 Stream Processors totales de la RX 5700 XT.
Se trata en cierto modo de Vega 64 (4 096 Stream Processors) y Vega 56 (3 584 Stream Processors). La diferencia reside en que Navi para cada Compute Unit cuenta con una segunda unidad escalar que se encarga de los problemas matemáticos. Adicionalmente dispone de un segundo programador que nos ofrece el doble de capacidad de instrucciones que la generación anterior. Es esto lo que la hace mucho más eficiente en cargas de trabajo para juegos.

Diferencias con GCN importantes
GCN cuenta con cuatro unidades SIMD16. Básicamente cada unidad tiene la capacidad de procesar 16 elementos de manera simultánea, pero con un problema, la latencia y la usabilidad. GCN no puede procesar una instrucción en un único ciclo de reloj. Generalmente necesita cuatro ciclos de reloj para la ejecución de principio a fin. Esto no es problema si se realizan cálculos de cuatro pasos, como un sumador fusionado, pero no es eficiente en instrucciones simples.
Bajo este caso, si el pipeline no logra corregir la perdida de ciclos, la gráfica se vuelve ineficiente. Así que GCN es muy buena para instrucciones complejas como cálculos científicos, pero no es buena en juegos, a no ser que se canalice muy bien. Y es aquí donde reside el problema. Para dar el máximo potencial, GCN necesita cargas de trabajo complejas y una programación muy buena para sacar todo su rendimiento

RDNA esta más optimizada que GCN
Para corregir este problema, en vez de implementar un SIMD16 de cuatro instrucciones de reloj, se ha implementado un SIMD32 en RDNA. Las SIMD32 son dobles para un único ciclo de reloj, lo cual la hace mucho más eficiente en juegos. RDNA es más efectiva para juegos que GCN. Permite ejecutar un Wave32 completo en una unidad de ejecución más pequeña, pasando de un Wave64 en GCN a un SIMD32 de un único ciclo.
Se le permite al compilador la elección mediante una llamada en base a sorteo, si quiere ejecutar Wave32 o Wave64. Eso sí, siempre bajo SIMD32 en funciones de carga de trabajo. Se consigue mejorar el paralelismo, permitiendo combinar dos Compute Units adyacentes. Esto lo que nos permite es crear un grupo de trabajo más grande para tratar de reducir la latencia

Latencia baja, mejora en la caché y mejora en monohilo
Explicado de manera sencilla, se pasa de GCN a RDNA para reducir la latencia, mejor el rendimiento en un único subproceso y mejorar la eficiencia de caché. Sencillamente se ofrece la realización de un trabajo más útil por Compute Unit y por ciclo de reloj. Básicamente esta es la razón por la que no deberíamos comparar 40 Compute Units GCN con 40 Compute Units RDNA.
Ahora bien, ¿porqué centrarse en el rendimiento y la eficiencia de un solo subproceso cuando el gaming se basa en la paralelización. El motivo es que, pese a que existen decenas de miles de subprocesos corriendo, no es sencillo mantenerlos en GCN con una amplia gama de cargas de trabajo diversas. Aquí se entreven los grandes cambios de RDNA.

Suponiendo que sus instrucciones no tengan demasiadas dependencias, cuenten con unidades escalares y tengan una programación doble en más de un SIMD. Esto debería de ofrecer una mejora de rendimiento considerable y mayor eficiencia.
Radeon además ha cogido algo de Ryzen, concretamente han añadido caché L1 dedicado y se duplica el ancho de banda de carga de caché más próximo a la ALU. Así se consigue reducir la latencia cuando se accede a le memoria caché a todos los niveles. Con esto se mejora el ancho de banda efectivo, permaneciendo los datos solicitados se mantienen en caché en vez de obtener de memorias más lentas.
Optimización y mejoras para una mayor eficiencia
Son muchas las mejoras realizadas. Se destaca que en RDNA se ha mejorado la compresión del color mediante el pipeline. En gráficos realiza una compresión máxima, a todo lo que puede, para minimizar la cantidad de ancho de banda usado. Se ha mejorado el algoritmo de compresión del color delta, permitiendo que los shaders puedan leer y escribir datos de color comprimidos directamente. La visualización del chip puede leer directamente los datos comprimidos y almacenados en el subsistema de memoria.
Como ya hemos comentado con las mejoras de las CU, se busca también aumentar el ancho de banda disponible y ser más eficiente en consumo, con respecto a GCN.
Conclusión
RDNA es una arquitectura optimizada por y para el gaming, mientras que GCN era una arquitectura hibrida. AMD se ha dado cuenta de que debe competir con NVIDIA en su terreno, en el gaming y por eso ha desarrollado unas gráficas optimizadas para juegos. Se alejan así de las memorias HBM2, mucho más caras que las memorias GDDR.
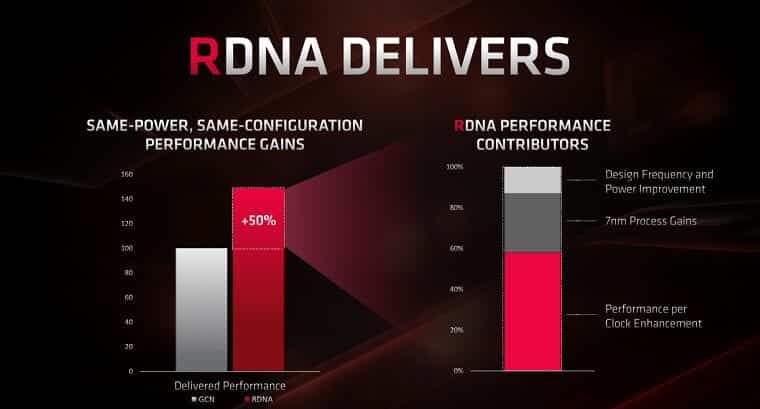
La propia AMD reconoce que, a iguales frecuencias, RDNA consigue un 25% más de rendimiento en juegos que su predecesora. Pero es que, si tenemos en cuenta la cantidad de CU y que se basa en la litografía de 7nm, la mejora puede ser del 50% o más. No será hasta la segunda iteración de Navi cuando veamos puramente RDNA y veamos de que es capaz.



